
Explainable AI: Detecting Out-of-Distribution Samples and Adversarial Attacks
Hello, mates. In this weblog submit, an interpretable design of unsupervised deep convolutional neural neighborhood & lstm autoencoders based real-time anomaly detection from high-dimensional heterogeneous/homogeneous time assortment data is obtainable.
This design is now built-in, as a model new choices part of the package deal deal “msda”. More particulars might be found on the GitHub internet web page proper right here
What’s new in MSDA v1.10.0?
MSDA is an open provide low-code time-series featured library in Python that objectives to cut back the hypothesis to insights cycle time in a time-series, multi-sensor data analysis & experiments. MSDA is straightforward, simple to utilize and low-code. It permits prospects to hold out end-to-end proof-of-concept experiments shortly and successfully. The module identifies events inside the multidimensional time assortment by capturing the variation and sample to find out a relationship aimed within the path of determining the correlated choices serving to in perform selection from raw sensor indicators. Also, it provides a provision to precisely detect the anomalies in real-time streaming data an unsupervised deep convolutional neural neighborhood & moreover a lstm autoencoders based detectors are designed to run on GPU/CPU. Finally, a recreation theoretic methodology is used to elucidate the output of the constructed anomaly detector model.
The package deal deal incorporates:-
- Time assortment analysis.
- The variation of each sensor column wrt time (rising, decreasing, equal).
- How each column values varies wrt totally different column, and the utmost variation ratio between each column wrt totally different column.
- Relationship establishment with sample array to find out most relevant sensor.
- User can select window measurement and then look at frequent value and commonplace deviation all through each window for each sensor column.
- It provides rely of growth/decay value for each sensor column values above or beneath a threshold value.
- Feature Engineering a) Features involving sample of values all through quite a few aggregation residence home windows: change and cost of change in frequent, std. deviation all through window. b) Ratio of changes, growth cost with std. deviation. c) Change over time. d) Rate of change over time. e) Growth or decay. f) Rate of growth or decay. g) Count of values above or beneath a threshold value.
- ** Unsupervised deep time-series anomaly detector. **
- ** Game theoretic methodology to elucidate the time-series data model. **
Features coming shortly***
- Explainable Forecasting with Logic Tensor Networks, Graph NN, and novel forecastGAN.
- ACF/PACF Analysis.
- Detection of False Trading Strategies Using Deep Unsupervised/Reinforcement Learning methodology.
- Optimization of the Trading Strategies (Long & Short Term) to maximise income decision making.
- 3D Distribution Maps for detection of MOX gasoline sensor indicators.
Who ought to make use of MSDA?
MSDA is an open provide library that anybody can use. In our view, the right viewers of MSDA is:
- Researchers for quick poc testing.
- Experienced Data Scientists who want to enhance productiveness.
- Citizen Data Scientists preferring a low code reply.
- Students of Data Science.
- Data Science Professionals and Consultants involved in establishing Proof of Concept initiatives.
Why ANOMALY is necessary?
What is an anomaly, and why should or not it is of any concern? In layman phrases, “Anomalies” or “outliers” are the knowledge elements in a data space, which can be irregular, or out of sample. Anomaly detection focuses on determining examples inside the data that someway deviate from what’s predicted or typical. Now, the question is, “How do you define one factor is irregular or outlier?” The quick rationale reply is all these elements that don’t adjust to the sample of the neighboring elements inside the sample space.
For any enterprise space, detecting suspicious patterns from an unlimited set of knowledge in essential. Say, as an illustration in banking space the fraudulent transactions pose a essential menace & loss/liabilities to the monetary establishment. In this weblog, we’ll try to review detecting anomalies from data with out teaching the model before-hand, on account of you could’t put together a model on data, which we don’t find out about! That’s the place your complete considered unsupervised learning helps. We will see two neighborhood architectures for establishing real-time anomaly detector, i.e., a) Deep CNN b) LSTM AutoEncoder
These neighborhood suits for detecting quite a lot of anomalies, i.e., degree anomalies, contextual anomalies, and discords in time assortment data. Since, the strategy is unsupervised, it requires no labels for anomalies. We use the unlabeled data to grab, and be taught the knowledge distribution that is used to forecast the standard habits of a time-series. The first construction is impressed from the IEEE paper DeepAnT, it consists of two parts: time assortment predictor and anomaly detector. The time assortment predictor makes use of deep convolutional neural neighborhood (CNN) to predict the next time stamp on the outlined horizon. This half takes a window of time assortment (used as a reference context) and makes an try to foretell the next time stamp. The predicted value is then handed to the anomaly detector half, which is answerable for labeling the corresponding time stamp as Non-Anomaly or Anomaly.
The second construction is impressed from this Nature paper Deep LSTM-based Stacked Autoencoder for Multivariate Time Series
Let first understand merely what’s AUTOENCODER neural neighborhood. The autoencoder construction is was once taught surroundings pleasant data illustration in an unsupervised methodology. There are three parts to an autoencoder: an encoding (enter) portion that compresses the knowledge, inside the course of learns a illustration (encoding) for the set of knowledge, a half that handles the compressed data (measurement low cost), and a decoder (output) portion that reconstructs the realized illustration as shut as doable to the distinctive enter from the compressed data whereas minimizing the overall loss function. So, merely when the knowledge is fed into an autoencoder, it is encoded and then compressed proper right down to a smaller measurement, and extra that smaller illustration is decoded once more to genuine enter. Next, permit us to understand, why LSTM is appropriate proper right here? What is LSTM? Long short-term memory (LSTM) is a neural neighborhood construction in a position to learning order dependencies in sequence prediction points. A LSTM neighborhood is a form of recurrent neural neighborhood (RNN). The RNN primarily suffers from vanishing gradients. Gradients embrace information, and over time, if the gradients vanish, then important localized information is misplaced. This is the place LSTM is handful as a result of it helps keep in mind the cell states preserving the data. The main thought is that the LSTM neighborhood has numerous “gates” inside it with expert parameters. Some of these gates administration the modules “output” and totally different gates administration “forgetting.” LSTM networks are good match for classifying, processing and making predictions based mostly totally on time assortment data, since there might be lags of unknown interval between important events in a time assortment.
An LSTM Autoencoder is an implementation of an autoencoder for sequence data using an Encoder-Decoder LSTM neighborhood construction.
Now, that we’ve now seen the important concepts of each neighborhood, permit us to bear the design of our every neighborhood as confirmed beneath. The DeepCNN consists of two convolutional layers. Typically, CNN consists of a sequence of layers which contains convolutional layers, pooling layers, and completely associated layers. Each convolutional layer normally has two phases. In the first stage, the layer performs the mathematical operation generally known as convolution which results in linear activations. In the second stage, a non-linear activation function is utilized on each linear activation. Like totally different neural networks, the CNN moreover makes use of teaching data to adapt its parameters (weights and biases) to hold out the coaching job. The parameters of the neighborhood are optimized using ADAM optimizer. The kernel measurement, number of filters might be tuned extra to hold out increased counting on the dataset. Further, the dropout, learning cost, and so forth. might be improbable tune to validate the effectivity of the neighborhood. The loss function used was the MSELoss (squared L2 norm) that measures the suggest squared error between each side inside the enter ‘x’ and objective ‘y’. The LSTMAENN consists of stacked numerous LSTM layers with input_size — The number of anticipated choices inside the enter x, hidden_size — The number of choices inside the hidden state h, num_layers — Number of recurrent layers (Default:1), and so forth. For additional particulars refer proper right here. To stay away from the scope of deciphering the detected noise inside the data as anomalies, we are going to tune the additional hyper-parameters like ‘lookback’ (time assortment window measurement), fashions in hidden layers, and many additional.
Unsupervised Full stack deep learning Anomaly Models
DeepCNN(
(conv1d_1_layer): Conv1d(10, 16, kernel_size=(3,), stride=(1,))
(relu_1_layer): ReLU()
(maxpooling_1_layer): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv1d_2_layer): Conv1d(16, 16, kernel_size=(3,), stride=(1,))
(relu_2_layer): ReLU()
(maxpooling_2_layer): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten_layer): Flatten()
(dense_1_layer): Linear(in_features=80, out_features=40, bias=True)
(relu_3_layer): ReLU()
(dropout_layer): Dropout(p=0.25, inplace=False)
(dense_2_layer): Linear(in_features=40, out_features=26, bias=True)
)

inspiration from this IEEE paper - https://ieeexplore.ieee.org/doc/8581424
- ** LSTM Autoencoder **
LSTMAENN(
(lstm_1_layer): LSTM(26, 128)
(dropout_1_layer): Dropout(p=0.2, inplace=False)
(lstm_2_layer): LSTM(128, 64)
(dropout_2_layer): Dropout(p=0.2, inplace=False)
(lstm_3_layer): LSTM(64, 64)
(dropout_3_layer): Dropout(p=0.2, inplace=False)
(lstm_4_layer): LSTM(64, 128)
(dropout_4_layer): Dropout(p=0.2, inplace=False)
(linear_layer): Linear(in_features=128, out_features=26, bias=True)
)

inspiration from proper right here – https://www.nature.com/articles/s41598-019-55320-6
Now, that we’ve now designed the neighborhood architectures. Next, we’ll bear the extra steps with hands-on demonstration as given beneath.
Getting Started
1) Install the package deal deal
The finest choice to arrange msda is using pip.
pip arrange msda
OR
$ git clone https://github.com/ajayarunachalam/msda
$ cd msda
$ python setup.py arrange
Notebook
!pip arrange msda
2) Import time-series data
Here, we’ll use the native climate data from proper right here. This dataset is compiled from numerous public sources. The dataset consists of every day temperatures and precipitation from 13 Canadian centres. Precipitation is each rain or snow (attainable snow in winter months). In 1940, there’s every day data for seven out of the 13 centres, nevertheless by 1960 there’s every day data from all 13 centres, with the occasional missing value. We have spherical 80 years data (every day frequency of knowledge), and we have to decide the anomalies from that native climate data. As seen beneath this data has 27 choices, and spherical 30K data.
df = pd.read_csv('Canadian_climate_history.csv')
df.type
=============
(29221, 27)
3) Data validation, pre-processing, and so forth.
We start by checking for missing values, and impute these missing values.
The capabilities missing(), and impute() from Preprocessing & ExploratoryDataAnalysis class might be utilized to go looking out missing values, and filling the missing information. We are altering the missing values with the suggest values (due to this fact, modes=1). There are numerous utility capabilities inside these classes that may be utilized for profiling your dataset, handbook filtering of outliers, and so forth. Also, totally different selections supplied embody datetime conversions, getting descriptive stats of the knowledge, normality distribution verify, and so forth. For additional particulars peek proper right here
'''
Impute missing values with impute function (modes=0,1, 2, else use backfill)
0: impute with zero, 1: impute with suggest, 2: impute with median, else impute with backfill method
'''
ExploratoryDataAnalysis.impute(df=df, modes=1)
4) Post-processing data to enter into the anomaly detector
Next, we’re inputting data with no missing values, eradicating of undesirable fields, assert the timestamp self-discipline, and so forth. Here, the individual can enter the column to drop with their index value, and assert the timestamp self-discipline with their index value too. This returns two dataframes, one can have all the numerical fields with out timestamp index, whereas the alternative can have all the numerical fields with timestamp indexing. We wish to make use of 1 with the timestamp as index of knowledge for extra steps.
Anamoly.read_data(data=df_no_na, column_index_to_drop=0, timestamp_column_index=0)
5) Data processing with user-input time window measurement
The time window measurement (lookback measurement) is given as enter to the function data_pre_processing from the Anamoly class.
X,Y,timesteps,X_data = Anamoly.data_pre_processing(df=anamoly_df, LOOKBACK_SIZE=10)
With this function, we’re moreover normalizing the knowledge all through the range of [0,1] and then modifying the dataset by along with ‘time-steps’ as one different additional dimension. The thought is to remodel two-dimensional data set of the dimension from [Batch Size, Features] to three-dimensional data set [Batch Size, Lookback Size, Features]. For additional particulars look at proper right here.
6) Selecting custom-made individual selection enter configurations to teach the anomaly model
Using the set_config() function the individual can select from the deep neighborhood architectures, set time window measurement, tune the kernel measurement. The obtainable fashions — Deep Convolutional Neural Network, LSTM AUTOENCODERS, that could be given with doable values [‘deepcnn’, ‘lstmaenn’]. We choose the time-series window measurement=10, and use the kernel measurement of three for the convolutional neighborhood.
MODEL_SELECTED, LOOKBACK_SIZE, KERNEL_SIZE = Anamoly.set_config(MODEL_SELECTED='deepcnn', LOOKBACK_SIZE=10, KERNEL_SIZE=3)
==================
MODEL_SELECTED = deepcnn
LOOKBACK_SIZE = 10
KERNEL_SIZE = 3
7) Training the chosen ANOMALY detector model
One can put together the model with each GPU/CPU based mostly totally on availability. The compute function will use GPU, if obtainable, in some other case, it could use the CPU property. The google colab makes use of NVIDIA TESLA K80 which might be essentially the most hottest GPU, whereas NVIDIA TESLA V100 is the First Tensor Core GPU. The number of epochs for teaching might be custom-made set. The machine getting used might be outputted on the console.
Anamoly.compute(X, Y, LOOKBACK_SIZE=10, num_of_numerical_features=26, MODEL_SELECTED=MODEL_SELECTED, KERNEL_SIZE=KERNEL_SIZE, epocs=30)
==================
Training Loss: 0.2189370188678473 - Epoch: 1
Training Loss: 0.18122351250783636 - Epoch: 2
Training Loss: 0.09276176958476466 - Epoch: 3
Training Loss: 0.04396845106961693 - Epoch: 4
Training Loss: 0.03315385463795454 - Epoch: 5
Training Loss: 0.027696743746250377 - Epoch: 6
Training Loss: 0.024318942805264566 - Epoch: 7
Training Loss: 0.021794179179027335 - Epoch: 8
Training Loss: 0.019968783528812286 - Epoch: 9
Training Loss: 0.0185430530715746 - Epoch: 10
Training Loss: 0.01731374272046384 - Epoch: 11
Training Loss: 0.016200231966590112 - Epoch: 12
Training Loss: 0.015432962290901867 - Epoch: 13
Training Loss: 0.014561152689542462 - Epoch: 14
Training Loss: 0.013974714691690522 - Epoch: 15
Training Loss: 0.013378228182289321 - Epoch: 16
Training Loss: 0.012861106097943028 - Epoch: 17
Training Loss: 0.012339938251426095 - Epoch: 18
Training Loss: 0.011948177564954476 - Epoch: 19
Training Loss: 0.011574006228333366 - Epoch: 20
Training Loss: 0.011185694509874397 - Epoch: 21
Training Loss: 0.010946418002639517 - Epoch: 22
Training Loss: 0.010724217305010896 - Epoch: 23
Training Loss: 0.010427865211985524 - Epoch: 24
Training Loss: 0.010206768034701313 - Epoch: 25
Training Loss: 0.009942568653453904 - Epoch: 26
Training Loss: 0.009779498535478721 - Epoch: 27
Training Loss: 0.00969111187656911 - Epoch: 28
Training Loss: 0.009527427295318766 - Epoch: 29
Training Loss: 0.009236675929400544 - Epoch: 30
8) Finding Anomalies
Once the teaching is completed, the next step is to go looking out the anomalies. Now, this brings us once more to our elementary question, i.e., how exactly can we estimate & trace what’s an anomaly?. One can use Anomaly Score, Anomaly Likelihood, and some present metrics like Mahalanobis distance-based confidence ranking and so forth. The Mahalanobis confidence ranking assumes that the intermediate choices of pre-trained neural classifiers adjust to class conditional Gaussian distributions whose covariances are tied for all distributions, and the conceitedness ranking for a model new enter is printed as a result of the Mahalanobis distance from the closest class conditional distribution. Anomaly Score is the fraction of energetic columns that weren’t predicted appropriately. In distinction, Anomaly Likelihood is the possibility {{that a}} given anomaly ranking represents an actual anomaly. In any dataset, there is usually a pure diploma of uncertainty that creates a positive “common” number of errors in prediction. Anomaly probability accounts for this pure diploma of error. Since, we don’t have the underside truth anomaly label, so in our case, we won’t use this metric. The find_anamoly() is used to detect anomalies by producing the hypothesis, and calculating losses, which can be the anomaly confidence scores for specific individual time stamps given inside the data set.
loss_df = Anamoly.find_anamoly(loss=loss, T=timesteps)
9) Plotting samples with confidence ranking: DeepCNN occasion
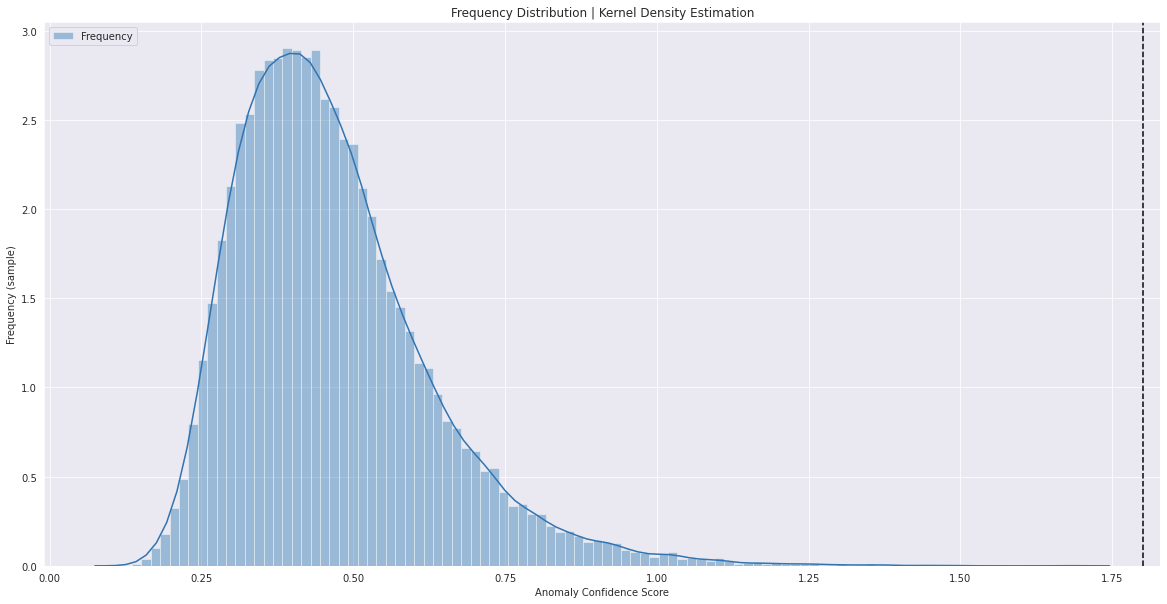
Next, we’ve to visualise the anomalies, the samples are assigned anomaly confidence ranking for each timestamp file. The plot_anamoly_results function might be utilized to plot the anomaly ranking with respect to frequencies (bins) & confidence ranking for every timestamp file.
Anamoly.plot_anamoly_results(loss_df=loss_df)
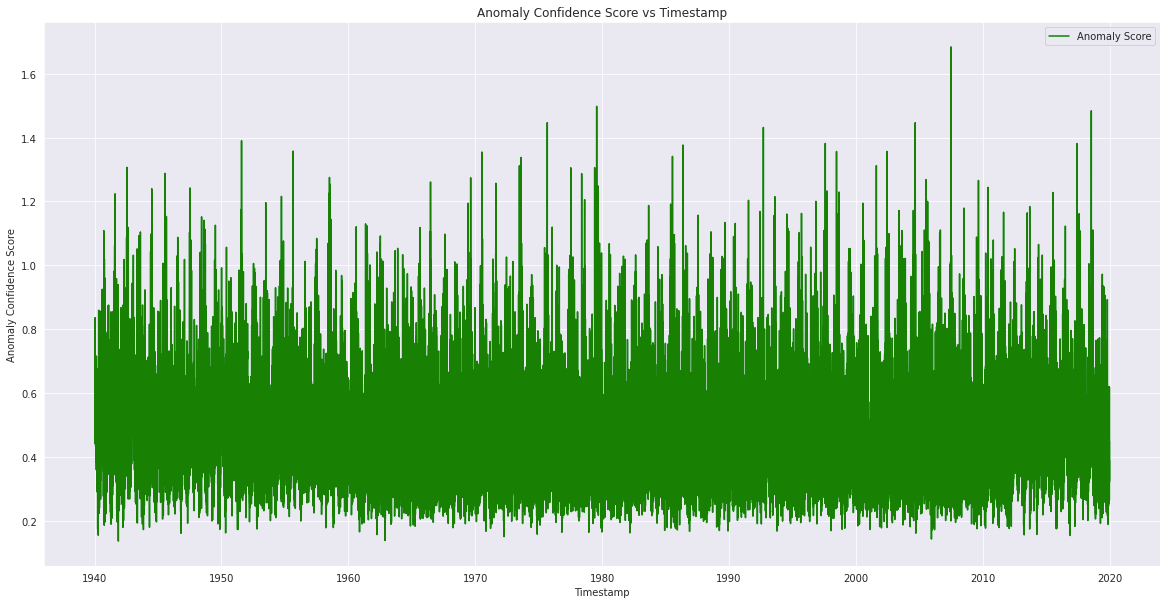
From the above graphs, one can preasume that the timestamps/circumstances, which has anomaly confidence scores higher equal to 1.2 are attainable examples that deviate from what’s predicted or typical, and thus might be dealt with as potential anomalies.
10) Intepretable outcomes of predictions from the anomaly detector — DeepCNN
Finally, a prototype of Explainable AI for the constructed time-series predictor is designed. Before, we bear this step, permit us to understand what’s need of interpretable fashions/explainable fashions.
Why Explainable AI (XAI) is the fun & need of the hour?
Data is all over the place, and machine learning can mine it for information. Representation learning would develop to be additional invaluable & extraordinarily necessary, if moreover the outcomes generated by machine learning fashions could be merely understood, interpreted, and trusted by folks. That is the place Explainable AI is obtainable in, thereby making points not a black area.
The explainable_results() makes use of the recreation theoretic methodology to elucidate the output of model. To understand, interpret, and perception the outcomes on the deep fashions at specific individual/samples diploma, we use the Kernel Explainer. One the fundemental properties of Shapley values is that they always sum as a lot as the excellence between the game consequence when all players are present, and the game consequence when no players are present. For machine learning fashions, due to this SHAP values of all the enter choices will always sum as a lot as the excellence between baseline (anticipated) model output, and the current model output for the prediction being outlined. The explainable_results function takes the enter value for the exact row/event/sample prediction that was made to be interpreted. It moreover takes the number of enter choices (X), and the time-series window measurement distinction (Y). We can get the explainable outcomes on the actual individual event diploma, and moreover on the batch of knowledge measurement (say as an illustration first 200 rows, remaining 50 samples, and so forth.)
Anamoly.explainable_results(X=anamoly_data, Y=Y, specific_prediction_sample_to_explain=10,input_label_index_value=16, num_labels=26)
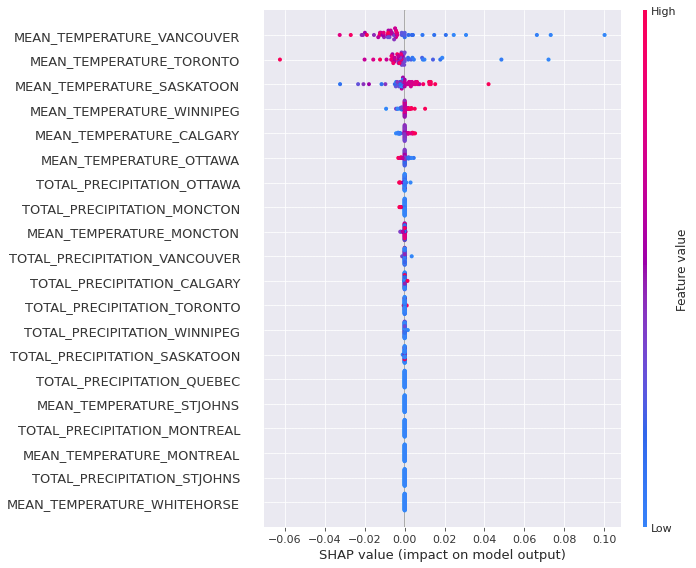
The above graph is the consequence for the tenth occasion/sample/file/event. It might be seen that the choices that contributed significantly to the corresponding resulted anomaly confidence ranking had been due to the temperature readings from the local weather stations of Vancouver, Toronto, Saskatoon, Winnipeg, Calgary.
Important Links
- Example Unsupervised Feature Selection Demo Notebook: https://github.com/ajayarunachalam/msda/blob/important/demo.ipynb
- Example Unsupervised Anomaly Detector & Explainable AI Demo Notebook: https://github.com/ajayarunachalam/msda/blob/important/demo1_v1.ipynb
Complete code is made obtainable proper right here. Refer this pocket e-book
CONTACT
Feel free to connect. You can attain me at ajay.arunachalam08@gmail.com
Always, proceed to study. Knowledge is the beginning of data 🙂
REFERENCES
From native explanations to worldwide understanding with explainable AI for bushes – https://www.nature.com/articles/s42256-019-0138-9
A Gentle Introduction to LSTM Autoencoders – https://machinelearningmastery.com/lstm-autoencoders/
DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series – https://ieeexplore.ieee.org/doc/8581424
Autoencoder – https://en.wikipedia.org/wiki/Autoencoder
Long short-term memory – https://en.wikipedia.org/wiki/Long_short-term_memory
Illustrated Guide to LSTM’s and GRU’s: A step-by-step rationalization – https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
Explainable artificial intelligence – https://en.wikipedia.org/wiki/Explainable_artificial_intelligence
What is explainable AI? – https://enterprisersproject.com/article/2019/5/what-explainable-ai
Essentials of Deep Learning : Introduction to Long Short Term Memory – https://www.analyticsvidhya.com/weblog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/
Understanding LSTM Networks – http://colah.github.io/posts/2015-08-Understanding-LSTMs/
A Gentle Introduction to Long Short-Term Memory Networks by the Experts – https://machinelearningmastery.com/gentle-introduction-long-short-term-memory-networks-experts/
Recurrent neural neighborhood – https://en.wikipedia.org/wiki/Recurrent_neural_network
Time assortment – https://en.wikipedia.org/wiki/Time_series
A Multivariate Time Series Guide to Forecasting and Modeling – https://www.analyticsvidhya.com/weblog/2018/09/multivariate-time-series-guide-forecasting-modeling-python-codes/
Convolutional Neural Network – https://en.wikipedia.org/wiki/Convolutional_neural_network
Stochastic gradient descent – https://en.wikipedia.org/wiki/Stochastic_gradient_descent
Artificial neural neighborhood – https://en.wikipedia.org/wiki/Artificial_neural_network
Adam: A Method for Stochastic Optimization – https://arxiv.org/abs/1412.6980
PyTorch – https://pytorch.org/
Stacked Long Short-Term Memory Networks – https://machinelearningmastery.com/stacked-long-short-term-memory-networks/
Rectifier (neural networks) – https://en.wikipedia.org/wiki/Rectifier_percent28neural_networkspercent29
Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech – https://arxiv.org/abs/1402.1128
Historical Climate Data – https://native climate.local weather.gc.ca/
Eighty years of Canadian native climate data – https://www.kaggle.com/aturner374/eighty-years-of-canadian-climate-data
Graphics processing unit – https://en.wikipedia.org/wiki/Graphics_processing_unit
NVIDIA Tesla V100 | NVIDIA – https://www.nvidia.com/en-gb/data-center/tesla-v100/
Tesla K80 – https://www.nvidia.com/en-gb/data-center/tesla-k80/
Why is the Mahalanobis Distance Effective for Anomaly Detection? – https://arxiv.org/abs/2003.00402
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks – https://arxiv.org/abs/1807.03888
Mahalanobis distance – https://en.wikipedia.org/wiki/Mahalanobis_distance
Stop explaining black area machine learning fashions for prime stakes picks and use interpretable – https://www.nature.com/articles/s42256-019-0048-x
From native explanations to worldwide understanding with explainable AI for bushes – https://www.nature.com/articles/s42256-019-0138-9
Game concept – https://en.wikipedia.org/wiki/Game_theory
Explainable machine-learning predictions for the prevention of hypoxaemia all through surgical process –https://www.nature.com/articles/s41551-018-0304-0
A Unified Approach to Interpreting Model Predictions – https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html
Welcome to the SHAP – https://shap.readthedocs.io/en/latest/