
Secret behind the Dimensionality Reduction for Data Scientist

Hello! I want to share my fascinating experience While I was working as a junior Data Scientist, I could even say I was a beginner all through that time on this info science space.
One of the prospects acquired right here to us for machine finding out implementation for their draw back assertion in each strategy unsupervised and supervised sorts, I believed it was going to be as regular mode of execution and course of because of based on my experience for small scale implementation or all through my teaching interval we use to have 25-30 choices and we fiddle with that and we use to predict or classify or clustering the dataset and share the consequence.
But this time they offer you tons of of choices, But I was considerably shocked and scared about the implementation and my head started spinning as one thing. Same time my Senior Data Scientist launched all people from the workers into the meeting room.
My Senior Data Scientist (Sr. DS) coined the new phrase to us, that is nothing nevertheless Dimensionality Reduction (OR) Dimension Reduction (OR) Curse Of Dimensionality, all newbies thought that he will elucidate one factor in Physis, we had little remembrance that we had come all through this time interval all through our teaching programme. then he started to sketch on the board (Refer fig-1). When we started 1-D, 2-D we’re lots cosy nevertheless 3-D and above our heads started to spin.
 1-D and 2-D
1-D and 2-D 3 – D
3 – DSr. DS has continued his lecture, all these sample footage are merely notable choices and we would fiddle with these, in a real-time state of affairs, many Machine Learning(ML) points comprise tons of of choices, so we discover your self teaching these fashions turned terribly gradual and will not give good choices for enterprise draw back and we couldn’t freeze the model, this case is the so-called “Curse Of Dimensionality” working. Then all of us started asking a question that how we should always at all times cope with this.
He took a protracted breath and proceed to share his experience in his private vogue. He started with a simple definition as follows.
What is Dimensionality?
We can say the number of choices in our dataset is called its dimensionality.
What is Dimensionality Reduction?
Dimensionality Reduction is the strategy of reducing the dimensions(choices) of a given dataset. Let’s say in case your dataset with 100 columns/choices and bringing the number of columns proper all the way down to 20-25. In simple phrases, you are altering the Cylinder/Sphere to a Circle or Cube proper right into a Plane in the two-dimensional home as beneath decide.
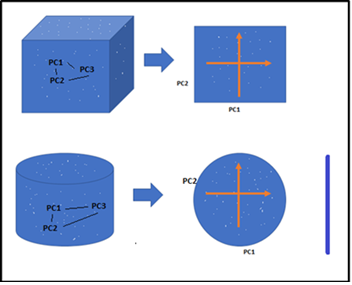 Converting 3D- 2D
Converting 3D- 2DHe has drawn beneath the relationship clearly between Modle Performance and Number of Features(Dimensions). As the number of choices will improve, the number of info elements moreover will improve proportionally. the straight assertion is that the additional choices will convey additional info samples, So we now have now represented all mixtures of choices and their values.
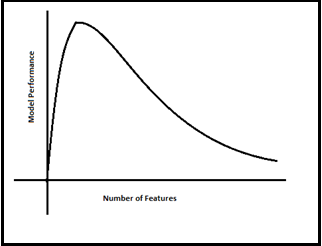 Modle Performance Vs Number of Features
Modle Performance Vs Number of FeaturesNow all people in the room obtained the actually really feel of what is “Curse Of Dimensionality” at a extremely extreme stage.
Benefits of doing Dimensionality Reduction
Suddenly, definitely one in all the workers members requested can he inform us the benefits of doing dimensionality low cost in the given dataset.
Our Sr. DS didn’t stop sharing his intensive knowledge further. He has continued as beneath.
There are numerous benefits if we go along with dimensionality low cost.
- It helps to remove redundancy in the choices and noise error elements lastly enhanced visualization of the given info set.
- Excellent memory administration train has been exhibited as a consequence of dimensionality low cost.
- Improving the effectivity of the model by choosing the correct choices by eradicating the pointless lists of choices from the dataset.
- Certainly, a lot much less number of dimensions (compulsory guidelines of dimensions) required a lot much less computing effectivity and apply the model sooner with improved model accuracy.
- Considerably reducing the Complexity and Overfitting of the common model and its effectivity.
Yes! it was an awe-inspiring spectacle, robustness, and dynamics of the “Dimensionality Reduction”. Now I can visualization the common revenue as beneath. hope it would help you too
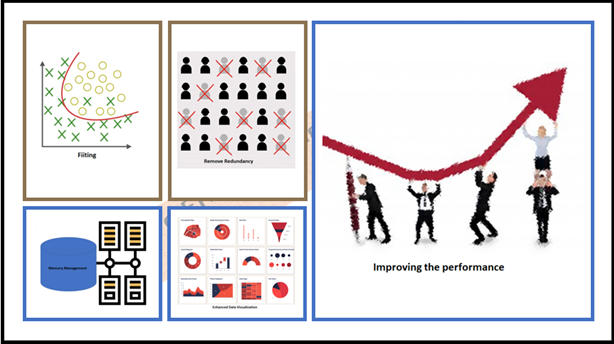
Benefits of Dimensionality Reduction.
What is subsequent, Of Course! We leap into the subsequent fundamental question that what are methods on the market for Dimensionality Reduction.
Dimensionality Reduction – Techniques
Our Sr. DS very lots continued his clarification on the methods whichever doable in Data Science space, broadly labeled into two approaches as talked about earlier considering selecting the best-fit Feature(s) or eradicating a lot much less obligatory Feature in the given extreme dimensional dataset. these high-level methods use to be referred to as Feature Selection or Feature Extraction, and principally, that is part of Feature Engineering. He has linked the dots fully.
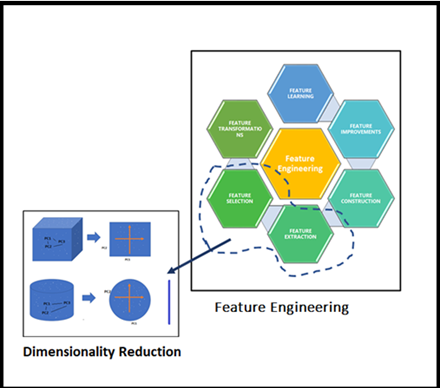 Locating Dimensionality Reduction in Feature Engineering family
Locating Dimensionality Reduction in Feature Engineering familyHe took us further in-depth concepts to know the large picture of utilized “Dimensionality Reduction” on the extreme dimensional dataset. Once we seen the beneath decide we able to relate the Feature Engineering and Dimensionality Reduction. Look at this decide the essence of Dimensionality Reduction properly by our Sr. DS is in it!
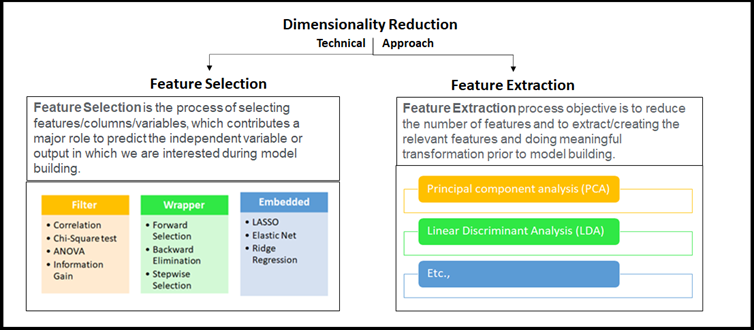
Everyone was to know the way one can apply all these using Phyton libraries with the help of simple coding. our Sr. DS requested me to convey vibrant markers and dusters

Sr. DS picked up the new blue marker and started explaining PCA with a simple occasion as follows, sooner than that he outlined what’s PCA stuff for dimensionality low cost.
Principal Component Analysis(PCA): PCA is a technique for dimensionality low cost of a given dataset, by rising interpretability with negligible information loss. Here the number of variables is decreasing, so it makes further analysis simpler. Which converts a set of correlated variables to a set of uncorrelated variables. Used for machine finding out predictive modeling. And he steered us to endure Eigenvector, Eigen Values
He took acquainted wines.csv for his quick analysis.

# Import all the compulsory packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns from sklearn.model_selection
import train_test_split from sklearn.linear_model
import LinearRegression from sklearn.metrics
import confusion_matrix from sklearn.metrics
import accuracy_score from sklearn
import metrics %matplotlib inline
import matplotlib.pyplot as plt
%matplotlib inline
wq_dataset = pd.read_csv('winequality.csv')
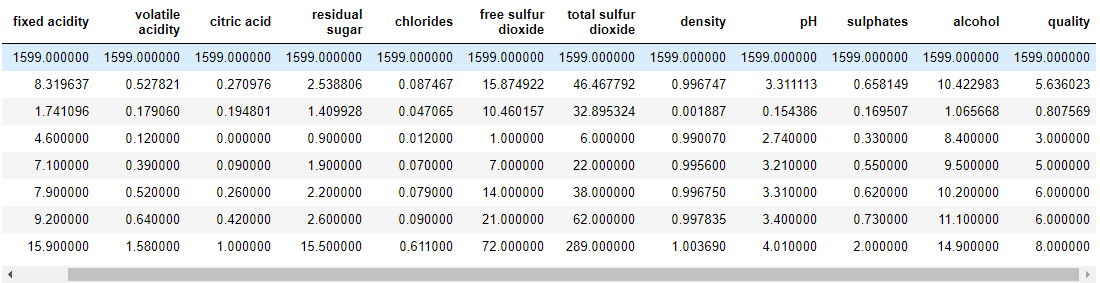
EDA on a given info set
wq_dataset.head(5)

wq_dataset.describe()
wq_dataset.isnull().any()

No Null price in the given info set, So good and we’re lucky.
Find correlations of each perform
correlations = wq_dataset.corr()['quality'].drop('prime quality') print(correlations)

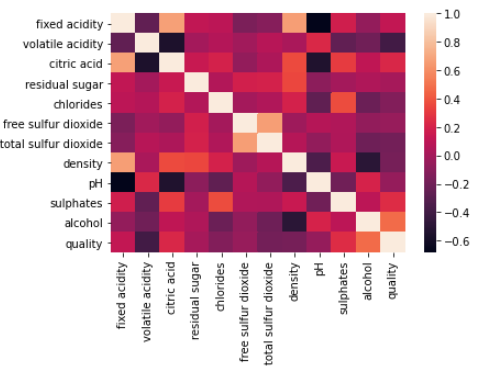
Correlation Representation using Heatmap
sns.heatmap(wq_dataset.corr()) plt.current()
x = wq_dataset[features] y = wq_dataset['quality']
[‘fixed acidity’, ‘volatile acidity’, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘alcohol’]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=3)
Training and Testing Shape
print('Traning info kind:', x_train.kind) print('Testing info kind:', x_test.kind)
Traning info kind: (1199, 8) Testing info kind: (400, 8)
PCA implementation for Dimensionality low cost (with 2 columns)
from sklearn.decomposition import PCA pca_wins = PCA(n_components=2) principalComponents_wins = pca_wins.fit_transform(x)
Naming them as principal half 1, principal half 2
pcs_wins_df = pd.DataPhysique(info = principalComponents_wins, columns = ['principal component 1', 'principal component 2'])
New principal components and their values.
pcs_wins_df.head()
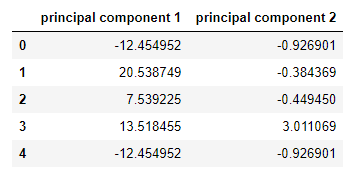
We all shocked when the above two columns with new column determine and values, We requested what happen to ‘mounted acidity’, ‘unstable acidity, ‘citric acid’, ‘chlorides’, ‘full sulfur dioxide’, ‘density’, ‘sulphates’, ‘alcohol’ columns. Sr. DS talked about all gone, now we now have now merely two columns after we utilized PCA for dimensionality low cost on given info and we will implement few fashions and that’s going to be the common strategy.
He has talked about one key phrase “variation per principal half”
that’s the fraction of variance outlined by a principal half is the ratio between the variance of that principal half and the full variance.
print('Explained variation per principal half: {}'.format(pca_wins.explained_variance_ratio_))
Explained variation per principal half: [0.99615166 0.00278501]
Followed by this he was demonstrated the following fashions
- Logistic Regression
- Random forest
- KNN
- Naive Bayes
Accuracy was increased and little distinction amongst each model, nevertheless he has talked about that’s for PCA implementation. Everyone in the room felt that we now have now completed an outstanding roller coaster. he has steered us to do hands-on completely different Dimensionality Reduction – Techniques.

Okay, Guys! Thanks for your time, hope I able to narrate my finding out experience of Dimensionality Reduction – Techniques in correct strategies proper right here, I perception it would help to proceed the journey to cope with difficult info set in machine finding out draw back assertion. Cheers!