

How to Use Pre-Labeled Data for AI Algorithms With High-Quality Requirements
In machine studying, information labeling is the method of figuring out objects or occasions on uncooked information (photographs, textual content recordsdata, movies, and many others.) and including a number of significant and informative labels to present context so {that a} machine studying mannequin can be taught from it. For instance, labels may point out whether or not a photograph accommodates a chook or automotive, which phrases had been uttered in an audio recording, or if an x-ray accommodates a tumor. Data labeling is required for a wide range of use circumstances, together with laptop imaginative and prescient, pure language processing, and speech recognition.
Successful machine studying fashions are constructed on the shoulders of huge volumes of high-quality annotated coaching information. But, the method of acquiring such high-quality information could be costly, difficult, and time-consuming, which is why typically corporations look for methods to automate the info annotation course of. While the automation could seem to be cost-effective, as we’ll see afterward, it additionally could include some pitfalls, hidden bills, trigger you to incur additional prices to attain the wanted annotation high quality stage in addition to put your undertaking timing in danger.
In this text, we take a better have a look at the hidden dangers and complexities of utilizing pre-labeled information which could be encountered alongside the best way of automating the labeling course of and the way it may be optimized. Let’s begin by getting an outline of what pre-labeled information is.

What is Pre-Labeled Data?
Pre-labeled information is the results of an automatic object detection and labeling course of the place a particular AI mannequin generates annotations for the info. Firstly the mannequin is skilled on a subset of floor fact information that has been labeled by people. Where the labeling mannequin has excessive confidence in its outcomes primarily based on what it has discovered thus far, it routinely applies labels to the uncooked information with good high quality. Often the standard of pre-labeled information could seem to be not adequate for tasks with excessive accuracy necessities. This contains all forms of tasks the place AI algorithms could have an effect on straight or not directly the well being and lives of people.
In fairly many circumstances, after the pre-labeled information is generated, there are doubts and issues about its accuracy. When the labeling mannequin has not ample confidence in its outcomes, it’ll generate labels and annotations of the standard, which is not sufficient to practice well-performing AI/ML algorithms. This creates bottlenecks and complications for AI/ML groups and forces them to add additional iterations within the information labeling course of to meet prime quality necessities of the undertaking. A very good answer right here might be to cross the routinely labeled information to specialists to validate the standard of annotations manually. This is why the step of validation turns into actually necessary since it might take away the bottlenecks and provides the AI/ML workforce peace of thoughts {that a} ample information high quality stage was achieved.
As we are able to see, there are some challenges corporations face with pre-labeled information when the ML mannequin was not correctly skilled on a specific subject material or if the character of uncooked information makes it troublesome and even unimaginable to detect and label all edge circumstances routinely. Now let’s take a better have a look at the potential points corporations want to be prepared for in the event that they select to use pre-labeled information.

Pre-Labeled Data May Not Be as Cost-Effective as You Think
One of the principle causes corporations select to use pre-labeled information is the upper value of handbook annotation. While from first look it might seem to be automation would lead to big value financial savings, in actual fact, it won’t. Different forms of information and numerous situations require the event and changes of various AI fashions for pre-labeling, which could be pricey. Therefore, for the event of such AI fashions to repay, the array of information for which it’s created should be massive sufficient to make the method of creating the mannequin cost-effective.
For instance, to develop ADAS and AV applied sciences, you want to contemplate a variety of totally different situations that embrace many variables after which listing these components. All of this creates a lot of combos, every of which can require a separate pre-annotation algorithm. If you might be counting on pre-labeled information to practice the AI system, you have to to always develop and regulate algorithms that may label all the information. It ends in a big enhance in prices. The price ticket of producing high-quality pre-annotations can develop exponentially relying on the number of information used within the undertaking, which might erase any value financial savings you might get hold of from hiring a devoted annotation workforce. However, if the info array is de facto massive, then the trail of pre-labeling information might be totally justified, however the high quality dangers of those annotations nonetheless should be taken into consideration, and typically, the handbook high quality validation step might be obligatory.
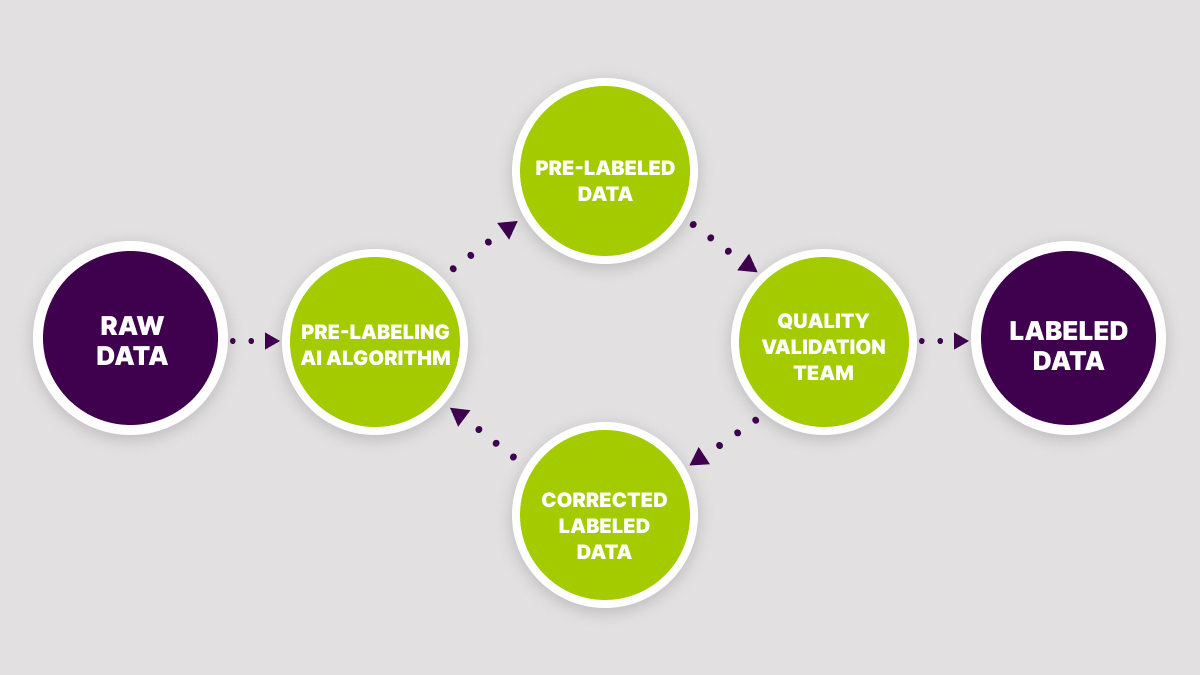
You Will Incur Data Validation Costs
In the earlier part, we talked that an ML system has restricted potential to be taught all the potential situations to label a dataset correctly, which implies that AI/ML groups will want a high quality validation step to be certain that the info labeling was accomplished appropriately and the wanted accuracy stage was reached. Algorithms for information pre-annotation have a tough time understanding advanced tasks with a lot of elements: the geometry of object detection, labeling accuracy, recognition of various object attributes, and many others. The extra advanced the taxonomy and the necessities of the undertaking the extra doubtless it’s to produce predictions of decrease high quality.
Based on the expertise of our work with shoppers, regardless of how nicely their AI/ML workforce developed the pre-annotation algorithms for circumstances with inconsistent information and complicated tips, their high quality continues to be nowhere close to the standard stage requirement, which normally is a minimal of 95% and could be as excessive as 99%. Therefore, the corporate will want to spend further assets on handbook information validation to preserve the high-quality information provide to make sure the ML system meets the wanted accuracy necessities.
A very good answer on this case might be to plan forward the standard validation step and the assets not to put the undertaking high quality and deadline in threat, however to have the wanted information accessible in time. Also the bottleneck could be simply eradicated by discovering a dependable skilled associate who can help your workforce with annotation high quality duties to launch the product with out delays and guarantee quicker time-to-market.

Some Types of Data Annotations Can Only Be Done by Humans
Certain annotation methodologies are troublesome to reproduce by way of the pre-labeling methodology. In common, for tasks the place the mannequin could carry dangers to life, well being, and security of individuals, it might be a mistake to depend on auto-labeled information alone. For instance, if we take one thing comparatively easy, like object detection with the assistance of 2D containers, frequent situations of the automotive business could be synthesized with sufficiently prime quality. However, the segmentation of advanced objects, with massive unevenness of object boundaries, will normally have a fairly low high quality with automated annotation.
In addition to this, usually there’s a want for important considering when annotating and categorizing sure objects, in addition to situations. For instance, landmarking of human skeletons could be synthesized, and the standard of pre-annotations could be passable over the course of coaching and refinement of the algorithm. However, if the undertaking contains information with a lot of totally different poses, in addition to occluded objects with a necessity to anticipate key factors for labeling, for such annotation, important considering might be obligatory to obtain a high-quality stage. Even essentially the most superior algorithms right this moment and within the close to future won’t have important considering, so such a course of is feasible solely by way of handbook annotation.
The submit How to Use Pre-Labeled Data for AI Algorithms With High-Quality Requirements appeared first on Datafloq.
