
Mastering Regression Analysis with Sklearn: Unleashing the Power of Sklearn Regression Models
What Are Sklearn Regression Models?
Regression fashions are a vital part of machine studying, enabling computer systems to make predictions and perceive patterns in information with out specific programming. Sklearn, a robust machine studying library, gives a variety of regression fashions to facilitate this course of.
Before delving into the particular regression strategies in Sklearn, let’s briefly discover the three sorts of machine studying fashions that may be carried out utilizing Sklearn Regression Models:
- bolstered studying,
- unsupervised studying
- supervised studying
These fashions permit computer systems to be taught from information, make choices, and carry out duties autonomously. Now, let’s take a more in-depth have a look at some of the hottest regression strategies obtainable in Sklearn for implementing these fashions.
Linear Regression
Linear regression is a statistical modeling approach that goals to ascertain a linear relationship between a dependent variable and a number of unbiased variables. It assumes that there’s a linear affiliation between the unbiased variables and the dependent variable, and that the residuals (the variations between the precise and predicted values) are usually distributed.
Working precept of linear regression
The working precept of linear regression entails becoming a line to the information factors that minimizes the sum of squared residuals. This line represents the finest linear approximation of the relationship between the unbiased and dependent variables. The coefficients (slope and intercept) of the line are estimated utilizing the least squares technique.
Implementation of linear regression utilizing sklearn
Sklearn offers a handy implementation of linear regression by way of its LinearRegression class. Here’s an instance of the best way to use it:
from sklearn.linear_model import LinearRegression
# Create an occasion of the LinearRegression mannequin
mannequin = LinearRegression()
# Fit the mannequin to the coaching information
mannequin.match(X_train, y_train)
# Predict the goal variable for brand spanking new information
y_pred = mannequin.predict(X_test)
Polynomial Regression
Polynomial regression is an extension of linear regression that enables for capturing nonlinear relationships between variables by including polynomial phrases. It entails becoming a polynomial operate to the information factors, enabling extra versatile modeling of advanced relationships between the unbiased and dependent variables.
Advantages and limitations of polynomial regression
The key benefit of polynomial regression is its skill to seize nonlinear patterns in the information, offering a greater match than linear regression in such instances. However, it may be vulnerable to overfitting, particularly with high-degree polynomials. Additionally, decoding the coefficients of polynomial regression fashions might be difficult.
Applying polynomial regression with sklearn
Sklearn makes it easy to implement polynomial regression. Here’s an instance:
from sklearn.preprocessing import PolynomialOptions
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
# Create polynomial options
poly_features = PolynomialOptions(diploma=2)
X_poly = poly_features.fit_transform(X)
# Create a pipeline with polynomial regression
mannequin = make_pipeline(poly_features, LinearRegression())
# Fit the mannequin to the coaching information
mannequin.match(X_train, y_train)
# Predict the goal variable for brand spanking new information
y_pred = mannequin.predict(X_test)
In the code snippet above, X represents the unbiased variable values, X_poly comprises the polynomial options created utilizing PolynomialOptions, and y represents the corresponding goal variable values. The pipeline combines the polynomial options and the linear regression mannequin for seamless implementation.
Evaluating polynomial regression fashions
Evaluation of polynomial regression fashions might be accomplished utilizing related metrics as in linear regression, corresponding to MSE, R rating, and RMSE. Additionally, visible inspection of the mannequin’s match to the information and residual evaluation can present insights into its efficiency.
Polynomial regression is a robust instrument for capturing advanced relationships, but it surely requires cautious tuning to keep away from overfitting. By leveraging Sklearn’s performance, implementing polynomial regression fashions and evaluating their efficiency turns into extra accessible and environment friendly.
Ridge Regression
Ridge regression is a regularized linear regression approach that introduces a penalty time period to the loss operate, aiming to cut back the impression of multicollinearity amongst unbiased variables. It shrinks the regression coefficients, offering extra secure and dependable estimates.
The motivation behind ridge regression is to mitigate the points attributable to multicollinearity, the place unbiased variables are extremely correlated. By including a penalty time period, ridge regression helps stop overfitting and improves the mannequin’s generalization skill.
Implementing ridge regression utilizing sklearn
Sklearn offers a easy option to implement ridge regression. Here’s an instance:
from sklearn.linear_model import Ridge
# Create an occasion of the Ridge regression mannequin
mannequin = Ridge(alpha=0.5)
# Fit the mannequin to the coaching information
mannequin.match(X_train, y_train)
# Predict the goal variable for brand spanking new information
y_pred = mannequin.predict(X_test)
In the code snippet above, X_train represents the coaching information with unbiased variables, y_train represents the corresponding goal variable values, and X_test is the new information for which we need to predict the goal variable (y_pred). The alpha parameter controls the energy of the regularization.
To assess the efficiency of ridge regression fashions, related analysis metrics as in linear regression can be utilized, corresponding to MSE, R rating, and RMSE. Additionally, cross-validation and visualization of the coefficients’ magnitude can present insights into the mannequin’s efficiency and the impression of regularization.
Lasso Regression
Lasso regression is a linear regression approach that comes with L1 regularization, selling sparsity in the mannequin by shrinking coefficients in the direction of zero. It might be helpful for characteristic choice and dealing with multicollinearity.
Lasso regression can successfully deal with datasets with a big quantity of options and robotically choose related variables. However, it tends to pick just one variable from a gaggle of extremely correlated options, which could be a limitation.
Utilizing lasso regression in sklearn
Sklearn offers a handy implementation of lasso regression. Here’s an instance:
from sklearn.linear_model import Lasso
# Create an occasion of the Lasso regression mannequin
mannequin = Lasso(alpha=0.5)
# Fit the mannequin to the coaching information
mannequin.match(X_train, y_train)
# Predict the goal variable for brand spanking new information
y_pred = mannequin.predict(X_test)
In the code snippet above, X_train represents the coaching information with unbiased variables, y_train represents the corresponding goal variable values, and X_test is the new information for which we need to predict the goal variable (y_pred). The alpha parameter controls the energy of the regularization.
Evaluating lasso regression fashions
Evaluation of lasso regression fashions might be accomplished utilizing related metrics as in linear regression, corresponding to MSE, R rating, and RMSE. Additionally, analyzing the coefficients’ magnitude and sparsity sample can present insights into characteristic choice and the impression of regularization.
Support Vector Regression (SVR)
Support Vector Regression (SVR) is a regression approach that makes use of the ideas of Support Vector Machines. It goals to discover a hyperplane that most closely fits the information whereas permitting a tolerance margin for errors.
SVR employs kernel features to remodel the enter variables into higher-dimensional characteristic house, enabling the modeling of advanced relationships. Popular kernel features embody linear, polynomial, radial foundation operate (RBF), and sigmoid.
Implementing SVR with sklearn
Sklearn gives an implementation of SVR. Here’s an instance:
from sklearn.svm import SVR
# Create an occasion of the SVR mannequin
mannequin = SVR(kernel='rbf', C=1.0, epsilon=0.1)
# Fit the mannequin to the coaching information
mannequin.match(X_train, y_train)
# Predict the goal variable for brand spanking new information
y_pred = mannequin.predict(X_test)
In the code snippet above, X_train represents the coaching information with unbiased variables, y_train represents the corresponding goal variable values, and X_test is the new information for which we need to predict the goal variable (y_pred). The kernel parameter specifies the kernel operate, C controls the regularization, and epsilon units the tolerance for errors.
Evaluating SVR fashions
SVR fashions might be evaluated utilizing customary regression metrics like MSE, R rating, and RMSE. It’s additionally useful to investigate the residuals and visually examine the mannequin’s match to the information for assessing its efficiency and capturing any patterns or anomalies.
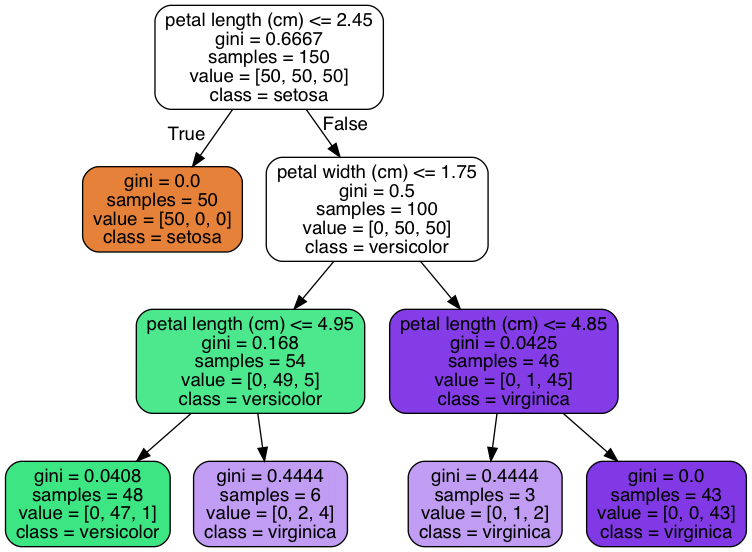
Decision Tree Regression
Decision tree regression is a non-parametric supervised studying algorithm that builds a tree-like mannequin to make predictions. It partitions the characteristic house into segments and assigns a relentless worth to every area. For a extra detailed introduction and examples, you’ll be able to click on right here: determination tree introduction.

Applying determination tree regression utilizing sklearn
Sklearn offers an implementation of determination tree regression by way of the DecisionTreeRegressor class. It permits customization of parameters corresponding to most tree depth, minimal pattern break up, and the selection of splitting criterion.
Evaluation of determination tree regression fashions entails utilizing metrics like MSE, R rating, and RMSE. Additionally, visualizing the determination tree construction and analyzing characteristic significance can present insights into the mannequin’s conduct.
Random Forest Regression
Random forest regression is an ensemble studying technique that mixes a number of determination bushes to make predictions. It reduces overfitting and improves prediction accuracy by aggregating the predictions of particular person bushes.
Random forest regression gives robustness, handles high-dimensional information, and offers characteristic significance evaluation. However, it may be computationally costly and fewer interpretable in comparison with single determination bushes.
Implementing random forest regression with sklearn
Sklearn offers a straightforward option to implement random forest regression. Here’s an instance:
from sklearn.ensemble import RandomForestRegressor
# Create an occasion of the Random Forest regression mannequin
mannequin = RandomForestRegressor(n_estimators=100)
# Fit the mannequin to the coaching information
mannequin.match(X_train, y_train)
# Predict the goal variable for brand spanking new information
y_pred = mannequin.predict(X_test)
In the code snippet above, X_train represents the coaching information with unbiased variables, y_train represents the corresponding goal variable values, and X_test is the new information for which we need to predict the goal variable (y_pred). The n_estimators parameter specifies the quantity of bushes in the random forest.
Evaluating random forest regression fashions
Evaluation of random forest regression fashions entails utilizing metrics like MSE, R rating, and RMSE. Additionally, analyzing characteristic significance and evaluating with different regression fashions can present insights into the mannequin’s efficiency and robustness.
Gradient Boosting Regression
Gradient boosting regression is an ensemble studying approach that mixes a number of weak prediction fashions, sometimes determination bushes, to create a powerful predictive mannequin. It iteratively improves predictions by minimizing the errors of earlier iterations.
Gradient boosting regression gives excessive predictive accuracy, handles differing kinds of information, and captures advanced interactions. However, it may be computationally intensive and vulnerable to overfitting if not correctly tuned.

Utilizing gradient boosting regression in sklearn
Sklearn offers an implementation of gradient boosting regression by way of the GradientBoostingRegressor class. It permits customization of parameters corresponding to the quantity of boosting levels, studying charge, and most tree depth.
Evaluating gradient boosting regression fashions
Evaluation of gradient boosting regression fashions entails utilizing metrics like MSE, R rating, and RMSE. Additionally, analyzing characteristic significance and tuning hyperparameters can optimize mannequin efficiency. For a extra detailed introduction and examples, you’ll be able to click on right here: gradient boosting determination bushes in Python.
Conclusion
In conclusion, we explored numerous regression fashions and mentioned the significance of selecting the applicable mannequin for correct predictions. Sklearn’s regression fashions provide a robust and versatile toolkit for predictive evaluation, enabling information scientists to make knowledgeable choices based mostly on information.
The submit Mastering Regression Analysis with Sklearn: Unleashing the Power of Sklearn Regression Models appeared first on Datafloq.