
Your Data’s (Finally) In The Cloud. Now, Stop Acting So On-Prem
Imagine you have been constructing homes with a hammer and nails for many of your profession, and I gave you a nail gun. But as a substitute of urgent it to the wooden and pulling the set off, you flip it sideways and hit the nail with the gun as if it have been a hammer.
You would most likely assume it is costly and never overly efficient, whereas the location’s inspector goes to rightly view it as a security hazard.
Well, that is since you’re utilizing trendy tooling, however with legacy considering and processes. And whereas this analogy is not an ideal encapsulation of how some knowledge groups function after transferring from on-premises to a contemporary knowledge stack, it is shut.
Teams shortly perceive how hyper elastic compute and storage providers can allow them to deal with extra numerous knowledge sorts at a beforehand remarkable quantity and velocity, however they do not all the time perceive the influence of the cloud to their workflows.
So maybe a greater analogy for these lately migrated knowledge groups could be if I gave you 1,000 nail weapons…after which watched you flip all of them sideways to hit 1,000 nails on the identical time.
Regardless, the essential factor to know is that the fashionable knowledge stack does not simply assist you to retailer and course of larger knowledge sooner, it means that you can deal with knowledge essentially in another way to perform new targets and extract various kinds of worth.
This is partly because of the enhance in scale and pace, but additionally on account of richer metadata and extra seamless integrations throughout the ecosystem.
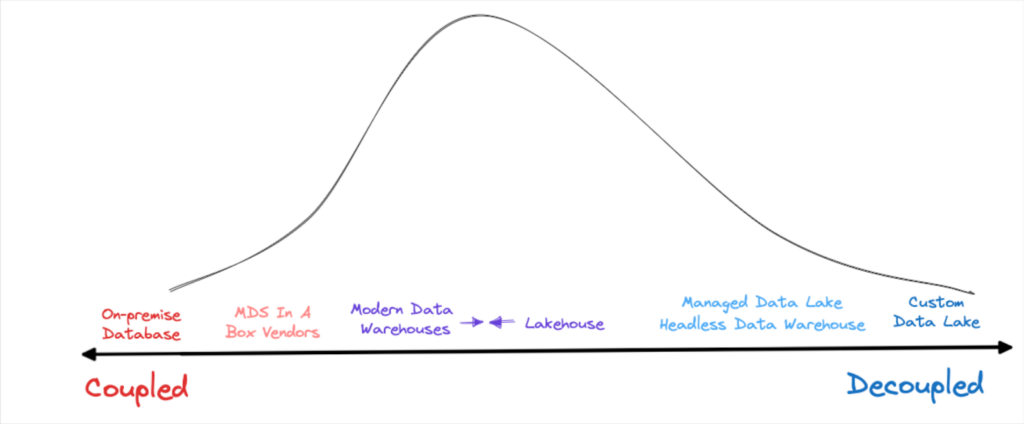
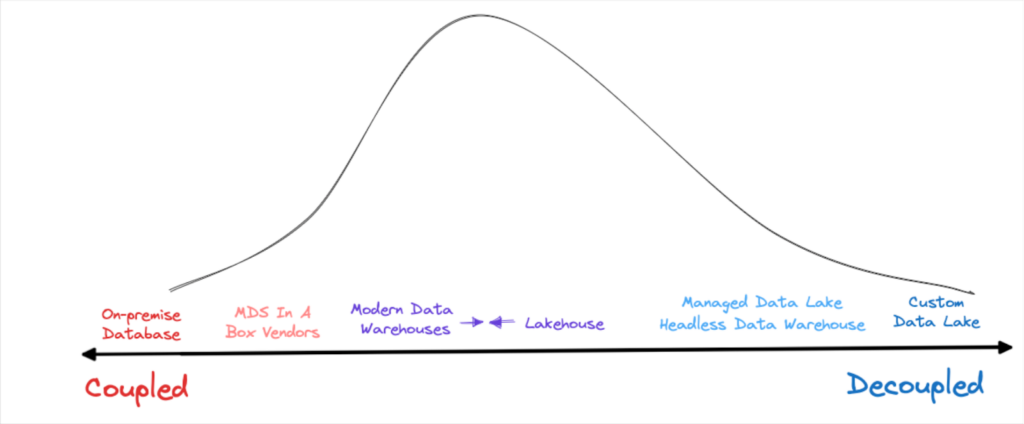
Platforms that separate storage and compute (however provide each providers) are among the many hottest for the benefits they supply. Image courtesy of Shane Murray.
In this publish, I spotlight three of the extra frequent methods I see knowledge groups change their habits within the cloud, and 5 methods they do not (however ought to). Let’s dive in.
3 Ways Data Teams Changed with the Cloud
There are causes knowledge groups transfer to a contemporary knowledge stack (past the CFO lastly releasing up funds). These use circumstances are sometimes the primary and best habits shift for knowledge groups as soon as they enter the cloud. They are:
Moving from ETL to ELT to speed up time-to-insight
You cannot simply load something into your on-premise database- particularly not if you would like a question to return earlier than you hit the weekend. As a consequence, these knowledge groups must fastidiously contemplate what knowledge to tug and easy methods to remodel it into its ultimate state usually by way of a pipeline hardcoded in Python.
That’s like making particular meals to order for each knowledge shopper somewhat than placing out a buffet, and as anybody who has been on a cruise ship is aware of, when it’s good to feed an insatiable demand for knowledge throughout the group, a buffet is the best way to go.
This was the case for AutoTrader UK technical lead Edward Kent who spoke with my group final 12 months about knowledge belief and the demand for self-service analytics.
“We need to empower AutoTrader and its prospects to make knowledge-informed selections and democratize entry to knowledge by a self-serve platform….As we’re migrating trusted on-premises methods to the cloud, the customers of these older methods must have belief that the brand new cloud-based applied sciences are as dependable because the older methods they’ve used up to now,” he mentioned.
When knowledge groups migrate to the fashionable knowledge stack, they gleefully undertake automated ingestion instruments like Fivetran or transformation instruments like dbt and Spark to go together with extra subtle knowledge curation methods. Analytical self-service opens up an entire new can of worms, and it isn’t all the time clear who ought to personal knowledge modeling, however on the entire it is a way more environment friendly means of addressing analytical (and different!) use circumstances.
Real-time knowledge for operational determination making
In the fashionable knowledge stack, knowledge can transfer quick sufficient that it now not must be reserved for these each day metric pulse checks. Data groups can reap the benefits of Delta stay tables, Snowpark, Kafka, Kinesis, micro-batching and extra.
Not each group has a real-time knowledge use case, however those who do are sometimes properly conscious. These are often corporations with important logistics in want of operational help or know-how corporations with sturdy reporting built-in into their merchandise (though an excellent portion of the latter have been born within the cloud).
Challenges nonetheless exist after all. These can generally contain operating parallel architectures (analytical batches and real-time streams) and making an attempt to achieve a degree of high quality management that isn’t attainable to the diploma most would love. But most knowledge leaders shortly perceive the worth unlock that comes from having the ability to extra straight help real-time operational determination making.
Generative AI and machine studying
Data groups are conscious about the GenAI wave, and plenty of business watchers suspect that this rising know-how is driving an enormous wave of infrastructure modernization and utilization.
But earlier than ChatGPT plagiarized generated its first essay, machine studying purposes had slowly moved from cutting-edge to plain greatest apply for plenty of knowledge intensive industries together with media, e-commerce, and promoting.
Today, many knowledge groups instantly begin analyzing these use circumstances the minute they’ve scalable storage and compute (though some would profit from constructing a greater basis).
If you lately moved to the cloud and have not requested the enterprise how these use circumstances might higher help the enterprise, put it on the calendar. For this week. Or at this time. You’ll thank me later.
5 Ways Data Teams Still Act Like They Are On-Prem
Now, let’s check out among the unrealized alternatives previously on-premises knowledge groups will be slower to use.
Side notice: I need to be clear that whereas my earlier analogy was a bit humorous, I’m not making enjoyable of the groups that also function on-premises or are working within the cloud utilizing the processes beneath. Change is difficult. It’s much more tough to do if you end up going through a relentless backlog and ever rising demand.
Data testing
Data groups which might be on-premises haven’t got the dimensions or wealthy metadata from central question logs or trendy desk codecs to simply run machine studying pushed anomaly detection (in different phrases knowledge observability).
Instead, they work with area groups to know knowledge high quality necessities and translate these into SQL guidelines, or knowledge checks. For instance, customer_id ought to by no means be NULL or currency_conversion ought to by no means have a adverse worth. There are on-premise based mostly instruments designed to assist speed up and handle this course of.
When these knowledge groups get to the cloud, their first thought is not to method knowledge high quality in another way, it is to execute knowledge checks at cloud scale. It’s what they know.
I’ve seen case research that learn like horror tales (and no I will not title names) the place a knowledge engineering group is operating hundreds of thousands of duties throughout 1000’s of DAGs to observe knowledge high quality throughout tons of of pipelines. Yikes!
What occurs while you run a half million knowledge checks? I’ll let you know. Even if the overwhelming majority move, there are nonetheless tens of 1000’s that can fail. And they’ll fail once more tomorrow, as a result of there isn’t any context to expedite root trigger evaluation and even start to triage and work out the place to begin.
You’ve one way or the other alert fatigued your group AND nonetheless not reached the extent of protection you want. Not to say wide-scale knowledge testing is each time and price intensive.
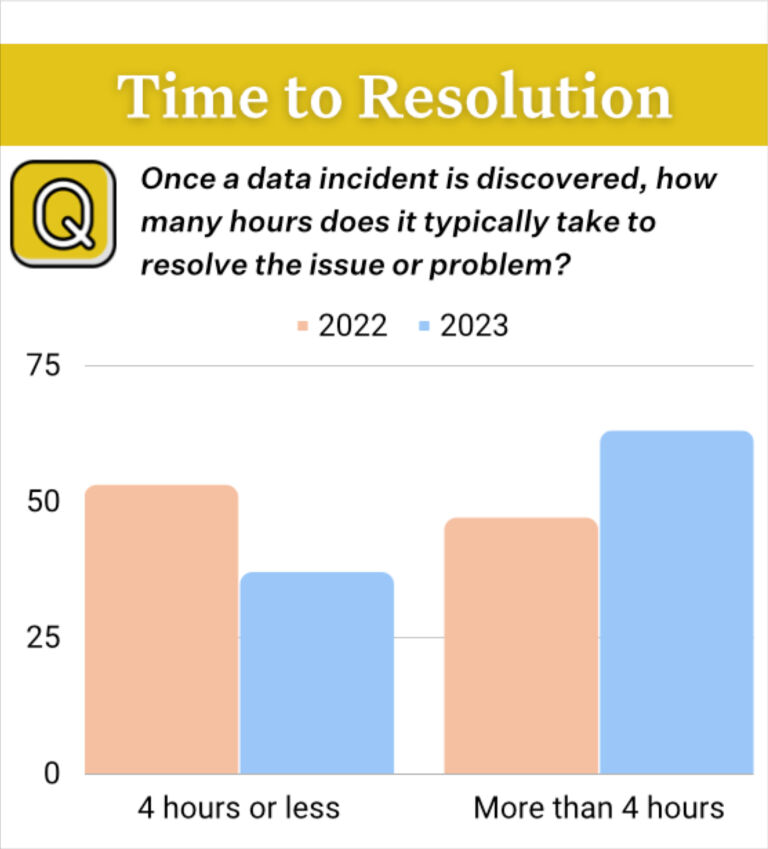
Finding knowledge anomalies is difficult, fixing them is tougher. Source.
Instead, knowledge groups ought to leverage applied sciences that may detect, triage, and assist RCA potential points whereas reserving knowledge checks (or customized screens) to probably the most clear thresholds on a very powerful values inside probably the most used tables.
Data modeling for knowledge lineage
There are many legit causes to help a central knowledge mannequin, and you have most likely learn all of them in an superior Chad Sanderson publish.
But, each now and again I run into knowledge groups on the cloud which might be investing appreciable time and assets into sustaining knowledge fashions for the only cause of sustaining and understanding knowledge lineage. When you might be on-premises, that’s basically your greatest wager until you need to learn by lengthy blocks of SQL code and create a corkboard so stuffed with flashcards and yarn that your important different begins asking in case you are OK.

(“No Lior! I’m not OK, I’m making an attempt to know how this WHERE clause modifications which columns are on this JOIN!”)
Multiple instruments inside the trendy knowledge stack-including knowledge catalogs, knowledge observability platforms, and knowledge repositories-can leverage metadata to create automated knowledge lineage. It’s only a matter of choosing a taste.
Customer segmentation
In the previous world, the view of the shopper is flat whereas we all know it actually ought to be a 360 world view.
This restricted buyer view is the results of pre-modeled knowledge (ETL), experimentation constraints, and the size of time required for on-premises databases to calculate extra subtle queries (distinctive counts, distinct values) on bigger knowledge units.
Unfortunately, knowledge groups do not all the time take away the blinders from their buyer lens as soon as these constraints have been eliminated within the cloud. There are sometimes a number of causes for this, however the largest culprits by far are good quaint knowledge silos.
The buyer knowledge platform that the advertising and marketing group operates remains to be alive and kicking. That group may gain advantage from enriching their view of prospects and prospects from different area’s knowledge that’s saved within the warehouse/lakehouse, however the habits and sense of possession constructed from years of marketing campaign administration is difficult to interrupt.
So as a substitute of focusing on prospects based mostly on the best estimated lifetime worth, it should be value per lead or value per click on. This is a missed alternative for knowledge groups to contribute worth in a straight and extremely seen strategy to the group.
Export exterior knowledge sharing
Copying and exporting knowledge is the worst. It takes time, provides prices, creates versioning points, and makes entry management nearly not possible.
Instead of profiting from your trendy knowledge stack to create a pipeline to export knowledge to your typical companions at blazing quick speeds, extra knowledge groups on the cloud ought to leverage zero copy knowledge sharing. Just like managing the permissions of a cloud file has largely changed the e-mail attachment, zero copy knowledge sharing permits entry to knowledge with out having to maneuver it from the host atmosphere.
Both Snowflake and Databricks have introduced and closely featured their knowledge sharing applied sciences at their annual summits the final two years, and extra knowledge groups want to begin taking benefit.
Optimizing value and efficiency
Within many on-premises methods, it falls to the database administrator to supervise all of the variables that might influence total efficiency and regulate as needed.
Within the fashionable knowledge stack, however, you usually see certainly one of two extremes.
In a number of circumstances, the function of DBA stays or it is farmed out to a central knowledge platform group, which may create bottlenecks if not managed correctly. More frequent nonetheless, is that value or efficiency optimization turns into the wild west till a very eye-watering invoice hits the CFO’s desk.
This usually happens when knowledge groups haven’t got the appropriate value screens in place, and there’s a significantly aggressive outlier occasion (maybe unhealthy code or exploding JOINs).
Additionally, some knowledge groups fail to take full benefit of the “pay for what you utilize” mannequin and as a substitute go for committing to a predetermined quantity of credit (sometimes at a reduction)…after which exceed it. While there may be nothing inherently mistaken in credit score commit contracts, having that runway can create some unhealthy habits that may construct up over time should you aren’t cautious.
The cloud permits and encourages a extra steady, collaborative and built-in method for DevOps/DataOps, and the identical is true in terms of FinOps. The groups I see which might be probably the most profitable with value optimization inside the trendy knowledge stack are those who make it a part of their each day workflows and incentivize these closest to the price.
“The rise of consumption based mostly pricing makes this much more important as the discharge of a brand new characteristic might probably trigger prices to rise exponentially,” mentioned Tom Milner at Tenable. “As the supervisor of my group, I examine our Snowflake prices each day and can make any spike a precedence in our backlog.”
This creates suggestions loops, shared learnings, and 1000’s of small, fast fixes that drive huge outcomes.
“We’ve received alerts arrange when somebody queries something that will value us greater than $1. This is kind of a low threshold, however we have discovered that it does not must value greater than that. We discovered this to be an excellent suggestions loop. [When this alert occurs] it is usually somebody forgetting a filter on a partitioned or clustered column and so they can study shortly,” mentioned Stijn Zanders at Aiven.
Finally, deploying charge-back fashions throughout groups, beforehand unfathomable within the pre-cloud days, is an advanced, however in the end worthwhile endeavor I’d wish to see extra knowledge groups consider.
Be a learn-it-all
Microsoft CEO Satya Nadella has spoken about how he intentionally shifted the corporate’s organizational tradition from “know-it-alls” to “learn-it-alls.” This could be my greatest recommendation for knowledge leaders, whether or not you might have simply migrated or have been on the forefront of knowledge modernization for years.
I perceive simply how overwhelming it may be. New applied sciences are coming quick and livid, as are calls from the distributors hawking them. Ultimately, it isn’t going to be about having the “most modernist” knowledge stack in your business, however somewhat creating alignment between trendy tooling, prime expertise, and greatest practices.
To do this, all the time be able to find out how your friends are tackling lots of the challenges you might be going through. Engage on social media, learn Medium, comply with analysts, and attend conferences. I’ll see you there!
The publish Your Data’s (Finally) In The Cloud. Now, Stop Acting So On-Prem appeared first on Datafloq.