Encounters with Logarithms in Data Science: Where They Arise
In the world of knowledge science, one of the vital continuously requested questions by aspiring fanatics is, “How a lot arithmetic do I actually need to know?” While the everyday response usually begins with statistics and extends to calculus and linear algebra, what usually stays unsaid is exactly the place you may encounter these mathematical ideas. In this dialogue, we’ll make clear one explicit mathematical idea: logarithms.
Data Transformation:
When information is collected, it seldom aligns completely with our analytical needs. There are cases the place we have to manipulate the info to reinforce our means to attract inferences, construct fashions, and uncover deeper insights. Data transformation entails rescaling the info utilizing mathematical features, and its function can vary from bettering mannequin efficiency to enhancing interpretability, and even addressing computational necessities. The utility of logarithmic transformations can reveal hidden insights inside the information, cut back skewness, and help in modeling, significantly when dealing with nonlinear relationships.
Demystifying Logistic Regression: Bridging the Gap Between Regression and Classification
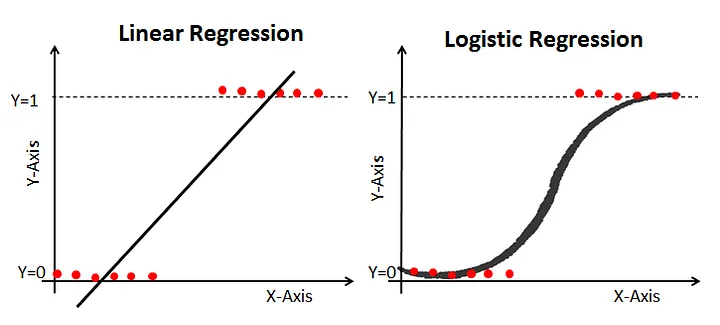
The time period “logistic regression” might sound deceptive, suggesting a regression activity, however in actuality, it’s a highly effective instrument primarily used for classification issues. If you have come throughout it in the context of generalized linear fashions (GLM) and located your self pondering, “The graph (illustrated beneath) would not seem linear in any respect,” you are not alone. However, it is essential to notice that logistic regression is certainly linear, however in a reworked sense.
In the graph, the Y-axis represents likelihood, which should all the time fall inside the vary of 0 to 1. However, in logistic regression, the Y-axis undergoes a metamorphosis, shifting from likelihood to the log(odds), which extends throughout your complete actual quantity line, starting from unfavourable infinity to optimistic infinity. Consequently, the coefficients in logistic regression convey beneficial data: they point out {that a} unit enhance in the explanatory variable corresponds to a rise in the log(odds) by the coefficient worth.

Image from DataCamp
Unraveling Log Likelihood: A Crucial Concept in Data Science
The time period “chance” is commonly encountered in information science, represented as L(distribution | information). While in on a regular basis language, “likelihood” and “chance” are typically used interchangeably, they’ve distinct meanings, though they could overlap in particular circumstances. This dialogue will not delve into the intricacies of their variations however will discover their functions in information science.
In sure situations, particularly in methods like Gaussian Naive Bayes, a number of likelihoods have to be calculated and multiplied. However, this course of can result in a computational problem generally known as “underflow” when dealing with extraordinarily small values near zero. To overcome this concern, information scientists flip to “log likelihoods” by taking the logarithms of chance values. This transformation shifts values from being near zero to changing into considerably distant from zero, successfully mitigating the underflow downside.
Cost Function:
In the realm of information science, the time period “price perform” refers to what we goal to optimize when becoming a mannequin. Some of those features, akin to “log loss,” incorporate logarithms as integral parts. So, when you encounter logarithms in price features, do not be shocked!
These are simply a few the distinguished areas the place logarithms play an important position in information science. It’s extremely seemingly that you will encounter them in different contexts as properly.
I hope you discovered this data fulfilling and insightful!
The put up Encounters with Logarithms in Data Science: Where They Arise appeared first on Datafloq.